Was bedeutet "End-to-End"-Überwachung wirklich?

Verschaffen Sie sich einen echten Überblick über die verschiedenen Umgebungen, um bessere Einblicke in die digitale Mitarbeitererfahrung zu erhalten.
Ein altes Sprichwort sagt, wenn man nur einen Hammer hat, sieht jedes Problem wie ein Nagel aus. Und das trifft in der IT-Welt mit Sicherheit zu.
Es gibt eine Vielzahl von Anbietern und Technologien, die behaupten, eine "End-to-End"-Überwachung von Systemen, Anwendungen, Anwender, Digital Employee Experience (DEX) und so weiter als Teil einer besseren, umfassenderen Digital Experience Management-Lösung zu bieten. Wenn man jedoch beginnt, die sprichwörtliche Zwiebel zu diesem Thema abzuschälen, wird klar, dass diese Technologien nur dann eine "End-to-End"-Transparenz bieten, wenn man mit der Definition des Wortes "Ende" wirklich flexibel ist.
Lassen Sie uns das näher erläutern.
Ein genauerer Blick auf die IT-Sichtbarkeit
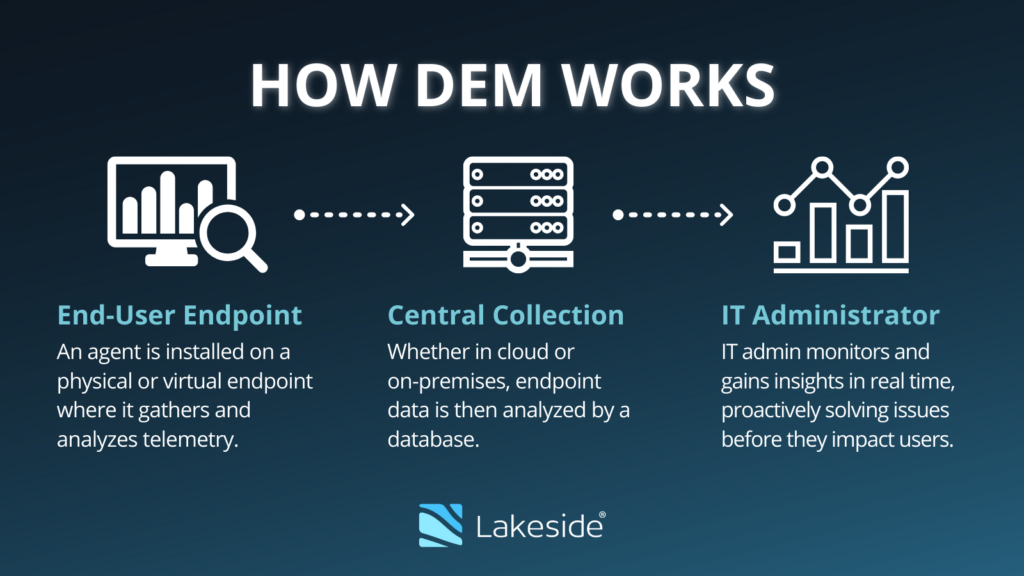
End-to-End-Monitoring, auch bekannt als Digital Experience Monitoring, ist der Prozess der Analyse von Daten über Infrastruktur, Geräte, Anwendungen und Dienste hinweg, um einen ganzheitlichen Überblick über digitale Umgebungen zu erhalten und zu erfahren, wie sich die Interaktionen der Endnutzer mit der Technologie auf die Qualität ihrer digitalen Erfahrungen auswirken Anwender. End-to-End-Monitoring ist eine wichtige Komponente des Digital Experience Management (DEM).
Wenn ich mich für die digitale Mitarbeitererfahrung, auch bekannt als Endbenutzererfahrung (EUX), eines bestimmten Systems oder IT-Dienstes interessiere, würde ich sicherlich mit dem beginnen, was den Endbenutzer beeinflusst:
- Reagiert das System auf Eingaben?
- Sind die Systeme frei von Abstürzen oder lästigen Anwendungshängern?
- Funktionieren die Systeme sowohl für Bürostandorte als auch für Fernzugriffsszenarien?
- Werden komplexe Aufgaben und Prozesse in einem angemessenen Zeitrahmen erledigt?
- Ist die Erfahrung des Endbenutzers konsistent?
Dies sind die Fragen, die Unternehmen als Ganzes oft beschäftigen.
In der Welt der IT wird das Thema Endbenutzererfahrung jedoch oft in eher technischen Begriffen diskutiert. Hinzu kommt, dass es keine zentrale Anlaufstelle für alle Systeme innerhalb einer größeren IT-Struktur gibt. Ein Beispiel: Es gibt ein Netzwerkteam (vielleicht sogar aufgeteilt in Local-Area-Networks, Wide-Area-Networks und Wireless-Technologien), es gibt ein Server-Virtualisierungsteam, es gibt ein Storage-Team, es gibt ein PC-Support-Team, es gibt verschiedene Anwendungsteams und viele weitere Silos.
Die auf dem Markt erhältlichen Überwachungs-Tools lassen sich im Grunde ebenfalls diesen Silos zuordnen. Im Großen und Ganzen gibt es Tools, die wirklich gut bei der Netzwerküberwachung sind, d. h. sie betrachten die Netzwerkinfrastruktur (Router, Switches usw.) sowie die Pakete, die durch die Infrastruktur fließen. Dank des OSI-Modells mit sieben Schichten stehen nicht nur Daten über Verbindungen, TCP-Ports, IP-Adressen und Netzwerklatenz zur Verfügung, sondern auch die Möglichkeit, die Nutzlast der Pakete selbst zu untersuchen. Letzteres bedeutet, dass man verstehen kann, ob es sich bei der Netzwerkverbindung um das HTTP-Protokoll für Webbrowsing, PCoIP oder ICA/HDX für Anwendungs- und Desktopvirtualisierung, SQL-Datenbankabfragen usw. handelt.
Da sich diese Art von Protokollinformationen in der obersten Schicht des Modells befindet, die auch als Anwendungsschicht bezeichnet wird, bezeichnen die Anbieter diese Art der Überwachung oft als "Anwendungsüberwachung", obwohl sie in Wirklichkeit wenig mit der Untersuchung der Anwendungen und ihres Verhaltens auf dem System zu tun hat. Trotz dieser Art von Details der Anwendungsschicht im Netzwerkstapel reichen die Daten nicht aus, um die Erfahrung des Endbenutzers zu ermitteln. Wir können vielleicht sehen, dass ein Webserver länger als erwartet braucht, um das angeforderte Objekt einer Webseite zurückzugeben, aber wir haben keine Ahnung, warum das so ist. Das liegt daran, dass die Netzwerküberwachung nur die Netzwerkpakete sieht - von dem Punkt an, an dem sie ein System verlassen und von einem anderen System empfangen werden und dann eine entsprechende Antwort in die andere Richtung geht - hin und her, aber keine Ahnung hat, was im Inneren der Systeme passiert, die miteinander kommunizieren.
Die Geschichte wiederholt sich auch in anderen Silos. Die Hypervisor-Teams sind ziemlich gut darin, festzustellen, dass eine bestimmte virtuelle Maschine mehr als ihren "gerechten Anteil" an den Ressourcen des physischen Servers verbraucht und daher andere Arbeitslasten dazu zwingt, auf CPU-Zyklen oder Speicherzuweisung zu warten. Der Schlüssel liegt darin, dass sie nicht wissen, welche Aktivität in welcher Arbeitslast eine Ressourcenspitze verursacht. Die Speicherteams können die Dimensionierung und Zuweisung von LUNs, die IOPS-Last auf dem Speichersystem und die Anforderungsvolumina sehr detailliert erfassen, aber sie wissen nicht, warum das Speichersystem zu einem bestimmten Zeitpunkt eine Spitze aufweist.
Die Desktop- oder PC-Support-Teams... oh, Moment - viele von ihnen haben kein Überwachungssystem, also raten sie im Grunde nur und bitten Anwender , das System neu zu starten, das Windows-Profil zurückzusetzen oder die Schuld auf das Netzwerk zu schieben. Bevor ich jetzt eine Menge Hass-Mails zu diesem Thema bekomme: Es ist wirklich schwierig, Endbenutzer-Support zu leisten, weil wir in der Regel nicht die Mittel haben, um zu sehen, was der Benutzer wirklich tut (und Anwender ist notorisch schlecht darin, die Symptome, die sie sehen, genau zu beschreiben).
Dann gibt es noch die Anwendungsüberwachung, die die Kunst und Wissenschaft der Bestimmung einer Basislinie und der Messung spezifischer Transaktionsausführungszeiten bei komplexen Anwendungen wie ERP-Systemen oder elektronischen Krankenakten darstellt. Dies ist sehr nützlich, um festzustellen, ob eine Konfigurationsänderung oder ein System-Upgrade systemische Auswirkungen hat, aber abgesehen vom tatsächlichen Zeitpunkt der Ereignisse gibt es nur wenig Einblick in die eigentliche Ursache der Dinge. (Liegt es am Server, an der Effizienz des Codes selbst, an der Belastung der Datenbank usw.)?
Warum End-to-End-Überwachung unerlässlich ist
All dies führt dazu, dass Anwender eine Leistungsverschlechterung erfährt, die sich auf die Qualität ihrer Arbeit auswirkt (oder schlimmer noch, auf ihre Fähigkeit, sinnvolle Arbeit zu leisten), und jedes Silo schaut dann auf seine spezifischen Dashboards und Überwachungswerkzeuge, nur um die Hände zu heben und zu rufen: "Das liegt nicht an mir!" Das ist kaum durchgängig, sondern nur eine Rechtfertigung dafür, weiterzumachen und die Anwender sich selbst zu überlassen.
Die meisten gut geführten IT-Organisationen haben ihre Betriebsbereiche ziemlich gut im Griff und können Infrastrukturprobleme schnell erkennen und beheben. Die große Mehrheit der Herausforderungen, die sich direkt auf Anwender auswirken, aber nicht zu einem totalen Systemausfall führen, haben jedoch mit dem Wettbewerb um Ressourcen zu tun. Dies gilt insbesondere im Zeitalter des serverbasierten Computings und der VDI. Ein Benutzer hat viel zu tun und alle anderen Anwender , die ihre Anwendungen oder Desktops auf demselben physischen Gerät gehostet haben, leiden darunter. Verschärft wird dies durch das Bestreben, die Kosten unter Kontrolle zu halten, indem VDI- und Anwendungs-Hosting-Umgebungen so dimensioniert werden, dass nur sehr wenig Spielraum für aufflackernde Benutzeranforderungen bleibt.
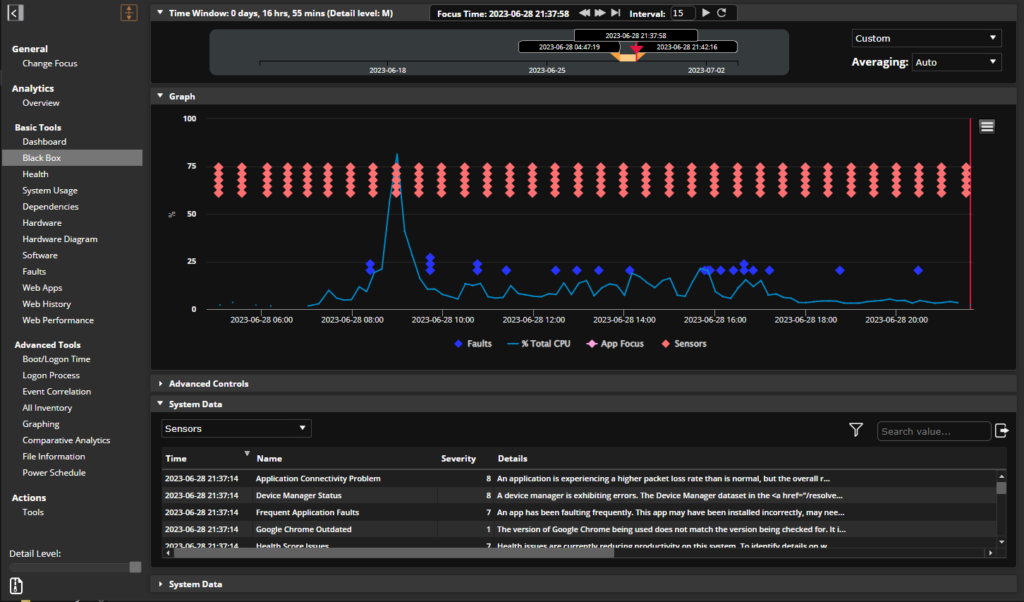
Genau aus diesem Grund ist es so wichtig, eine Lösung zur Überwachung der digitalen Erfahrung zu haben, die tiefe Einblicke in das Betriebssystem des Servers, des virtuellen Servers, des Desktops, des VDI-Images, des PCs, des Laptops und anderer Endpunkte bietet, um zu erkennen, was vor sich geht, welche Anwendungen laufen, abstürzen, sich falsch verhalten, Ressourcen verbrauchen usw. Nur eine umfassende, ganzheitliche Überwachungstechnologie (in Kombination mit den oben erwähnten Infrastrukturkomponenten) kann eine echte End-to-End-Transparenz der digitalen Mitarbeitererfahrung bieten, die für ein effektives Digital Experience Management unerlässlich ist. Denn es ist eine Sache, ein Problem oder eine "Langsamkeit" im Netzwerk zu bemerken, und eine ganz andere, die möglichen Grundursachen zu ermitteln, Muster zu erkennen und dann proaktiv Alarm zu schlagen und diese Probleme zu beheben.
Wie Lakeside End-to-End-Transparenz bietet
In Gesprächen mit IT-Organisationen, Systemintegratoren und Kunden hat sich im Laufe der Jahre ein gemeinsames Thema herauskristallisiert: IT-Administratoren möchten ALLE relevanten Daten zur Verfügung haben UND sie in einem einzigen Dashboard oder einer einzigen Ansicht dargestellt bekommen. Die Anbieter reagieren auf diesen Wunsch, indem sie ihre Produkte als "End-to-End" bezeichnen, obwohl die meisten Überwachungsaspekte, wie oben erläutert, gar nicht End-to-End sind.
Wenn Sie die gleichen Anforderungen haben, sollten Sie sich die Digital Experience Cloud von Lakeside Softwareansehen, die von SysTrack. Sie ist das führende Tool zum Sammeln von Tausenden von Datenpunkten von PCs, Desktops, Laptops, Servern, virtuellen Servern und virtuellen Desktops und kann nahtlos mit Quellen von Drittanbietern integriert werden, um verwertbare Daten bereitzustellen, die an einem Ort angezeigt werden können.
Wir sind keine Netzwerkexperten im Bereich der Paketanalyse, aber wir können Datenquellen von Netzwerkmonitoren anzapfen und sie zusammen mit dem Benutzerverhalten und der Systemleistung darstellen. Das ist eine leistungsstarke Kombination granularer Daten und bietet echte End-to-End-Funktionen als System of Record und als Teil einer erfolgreichen Plattform zur Verwaltung digitaler Erfahrungen.



Abonnieren Sie den Lakeside Newsletter
Erhalten Sie Plattformtipps, Versions-Updates, Neuigkeiten und mehr