Troubleshooting IT issues can be an extensive and strenuous process. If you’re administering a large environment the process can quickly become overwhelming. You might start by asking all kinds of questions – is it an isolated issue? How long has this been going on? How is this impacting the users? Are users affected who may never report this problem to the helpdesk? Asking questions is great, but if you don’t have the insight to get to the answers you’ll find yourself running in circles more often than not.
Luckily, SysTrack continuously monitors your environment and pays close attention to the user experience so you can get issues resolved before they have negative impacts on productivity and, ultimately, the bottom line.
Let’s take a common example to explore this a little more: A user is reporting that a particular application is unresponsive or crashing. The ticket makes its way to your desk with little helpful information. Maybe they reported a few instances with some vague descriptions of when it happened. Normally this would send you down the rabbit hole to interview the user and start running in those circles we mentioned, but here’s where SysTrack can help you avoid all that and use data to help you understand and resolve the issue.
Steps to incident resolution
A good place to start would be Site Visualizer. Just jump into the Observations area and open the Application Faults dataset to get a quick overview of what’s going on with the app. You’ll quickly see the number of faults this app has experienced, the number of affected systems, and when it first and last occurred. Right away you have some idea of how widespread the issue is and how long it’s been occurring.

Starting at a high-level overview like this can point you in the right direction for where to turn to next. If the app is only faulting on a single system you can probably assume the issue is system related and not app related and you may wish to simply reinstall the application on the affected system. But if it’s affecting a large portion of the user base then you know the app is part of the problem.
A quick right-click on the number of affected systems and then choosing Show Details will show you each system that’s been affected. Maybe they’re all part of the same group that received a software patch right around the time the app started faulting, or maybe they’re the only users with that app installed. Now you can work with the application vendor or your development team in the case of a homegrown application to help resolve this problem. Having easy access to this type of data dramatically reduces the time and effort it would have taken to answer these questions.
To dig a bit deeper into the issue you could target a particular user’s systems with Resolve. Open the Faults tool and you’ll be able to see details about the fault occurrences for the app in question, how it stacks up against the enterprise as a whole, and time-correlated information so you know exactly when each fault occurred.
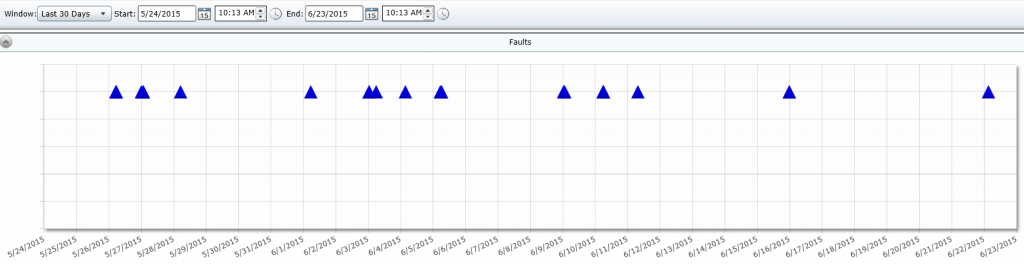
At this point you know how widespread the problem is, each and every system that’s been affected, and even the exact time of each individual occurrence. Once you’ve got all of this data you’re much better prepared to implement a solution.
To bring all of this back to the user experience you can even monitor the health of a system over time. Fix the case of the faulting app and see how the user’s health score has changed after the fix. This will give you a good idea of how their experience is going as well as if you’ve corrected the issue, and if there’s cause for concern due to some other problems. Avoiding that rabbit hole has never been easier.



Subscribe to Lakeside Updates
Receive product updates, DEX news, and more