

Many of the world’s largest companies’ operations came to a screeching halt earlier today with the global outages caused by CrowdStrike’s Falcon update for Windows. While CrowdStrike has identified the cause and issued a workaround, enterprises around the world must grapple with what to do next.
Could the CrowdStrike outage have been prevented?
With hindsight being 20/20, many are asking if this massive disruption could have been stopped proactively. Unfortunately, the answer is no. The outages were caused by an issue with a Falcon content update for Windows hosts. The update was pushed to any Windows systems that allows automatic updates, so it could not have been identified with proactive IT measures.
Outside of CrowdStrike recognizing the error before the update was released and automatically pushed out, no solution available today could have predicted or prevented the disruption.
With no preventative measures available and the impacts felt worldwide, many enterprises have entered crisis mode sorting out next steps.
How can businesses recover from the CrowdStrike outage?
The first step to recovering from these unprecedented outages is collecting data to understand the scope and impact. IT teams around the globe are asking:
- How many Windows systems do we have across our end users?
- Of those systems, which have CrowdStrike installed and could be vulnerable?
- What is the workflow to remediate these issues?
- And how do we best triage to ensure mission critical end user systems are repaired first?
- How will we ensure all users are back up and working once remediation has occurred?
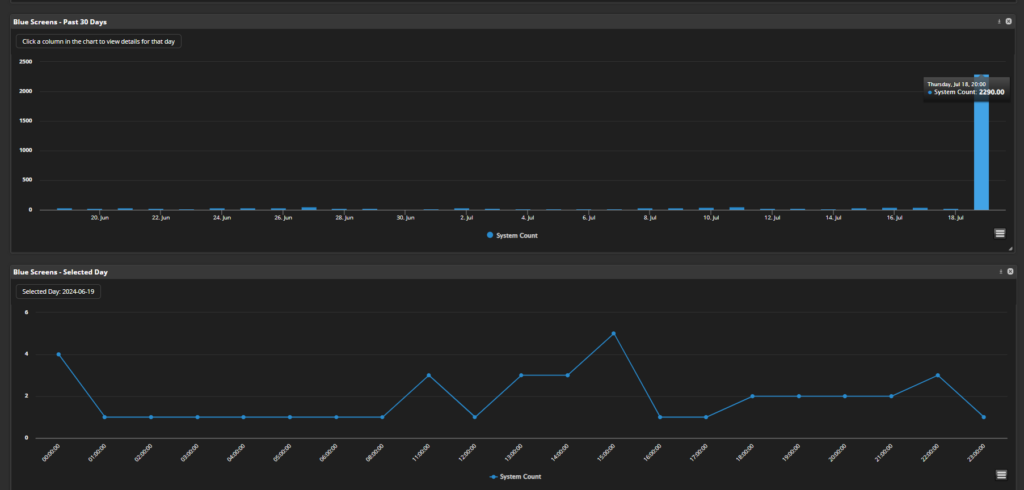
To answer any of these questions, organizations need data to offer visibility across their IT environments. Lakeside customers have this data at their fingertips in the SysTrack platform and are poised to begin recovery actions immediately.
We have developed a dashboard specific to the CrowdStrike outage to help customers understand the magnitude of the impact, triage repair of high-priority systems, and monitor the progress of remediation at scale. As the situation continues to unfold, we are updating the dashboard to reflect the most relevant data.
Through this dashboard, Lakeside customers can have a single pane of glass to identify all affected systems and begin to work through the remediation process. SysTrack also provides data on systems as they are repaired, so IT teams can quantify their efforts and monitor progress as they ensure systems are functioning normally again.
How can companies manage remediation at scale?
Millions of devices around the world will require manual intervention to fix, so the process will be take time. The more data IT teams have on the devices impacted, the faster they can react.
SysTrack can easily give IT teams insight on how many Windows systems have been affected in even the largest environments. It can also group end users by persona type so that IT teams can prioritize the remediation efforts for the most critical users first. This allows IT teams to get essential systems – like those used by healthcare clinicians, flight controllers, and financial traders – repaired first. Although today’s events were at a global-scale with enormous impacts, organizations face smaller outages daily.
The next time an outage hits, will you have enough data and visibility to take action immediately and recover faster? Only SysTrack collects 10,000 datapoints every 15 seconds from every endpoint in an IT environment. Don’t settle for less when business operations are on the line.



Subscribe to Lakeside Updates
Receive product updates, DEX news, and more


