
Using SysTrack to Resolve User Issues with SaaS
Cloud services have fundamentally shifted the landscape for the average consumer of IT resources, and too often this leaves the support organization stuck as the discoverer of the root cause of issues that span the endpoint, the network, and the supporting service providers. Our own organization is in a similar situation, having adopted Office 365 services for all users. However, because we’re consumers of our own dog food (figuratively—I only have a guinea pig), we’ve got the ability to pinpoint the real source of user-impacting problems. As an example, we recently had a user experience trouble with making and receiving calls with Skype for Business.
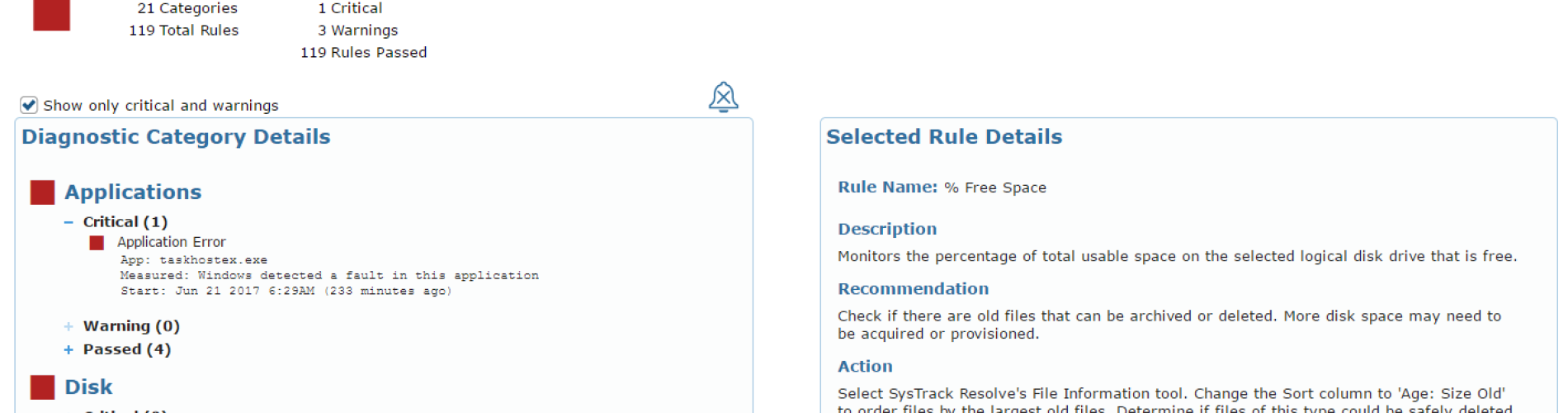
Our investigation starts at the point of interaction for the user. In Resolve, we’ve got the ability to look up the user in question and immediately start reviewing the context surrounding their performance issue.
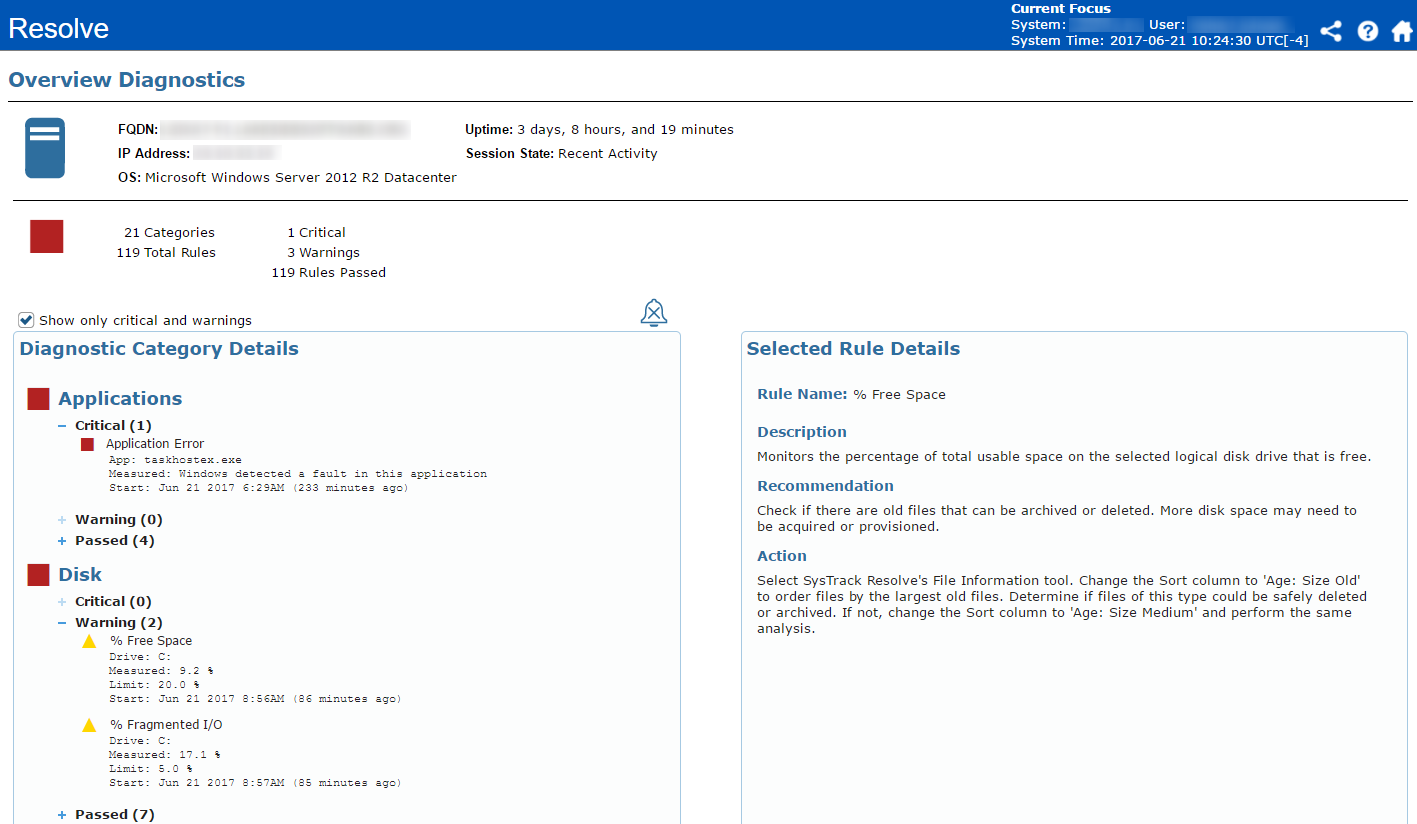
The RAG analysis provided in the overview indicates a handful of issues, but nothing directly related to Skype performance on the client itself. Further, there’s nothing impacting the network for the user or their NIC. That means we need to dig in a little deeper. This leads us to the Black Box area, which allows us to focus on the particulars of what was happening when the user had their issue.
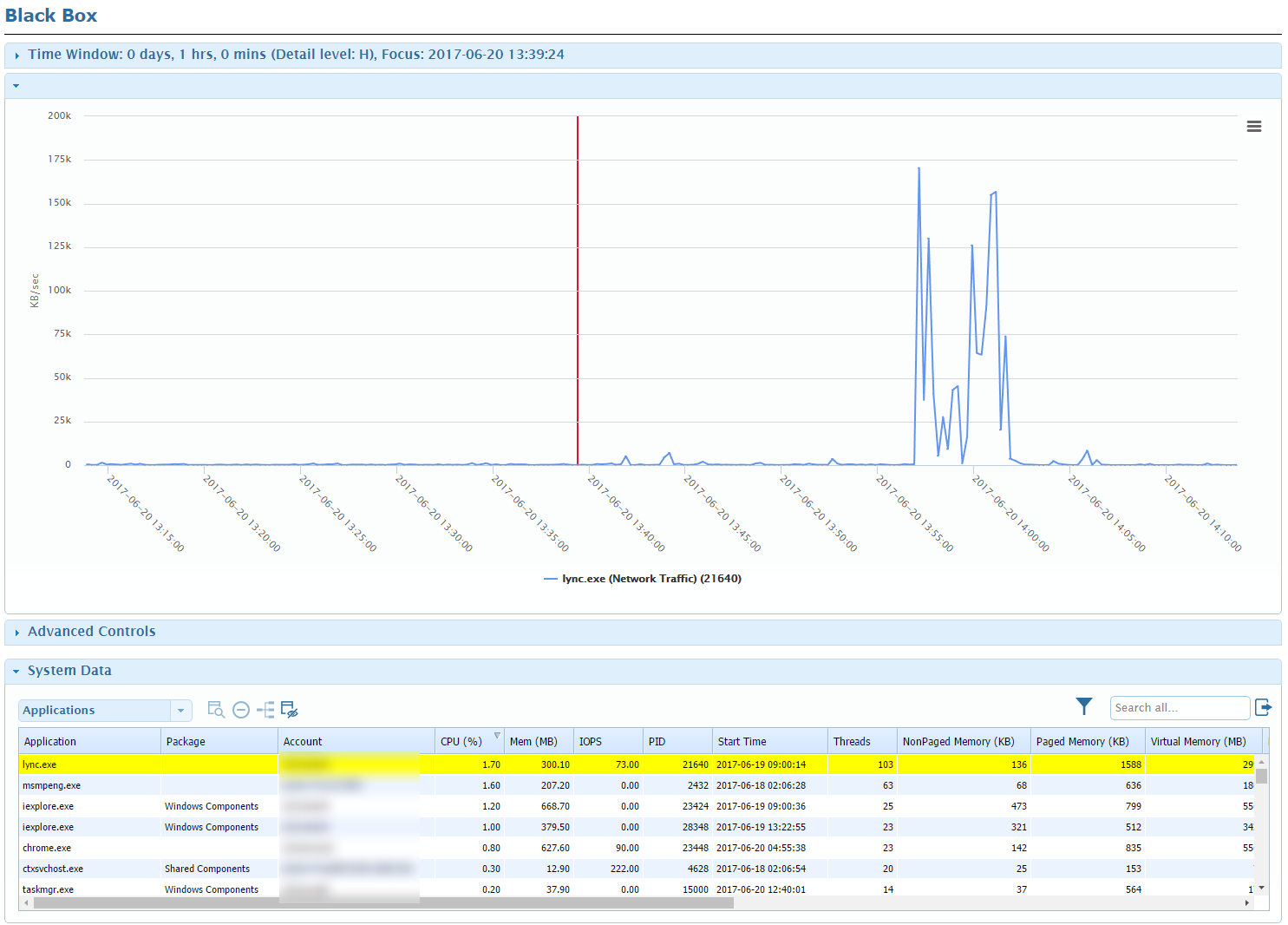
Selecting the time interval where they first started having an issue we notice something interesting: the Skype for Business app (lync.exe) shows essentially no network traffic. Kind of a curious turn of events, and it’s something we wanted to investigate further. Luckily, we’ve been doing some internal auditing work with service status reporting from Office 365.
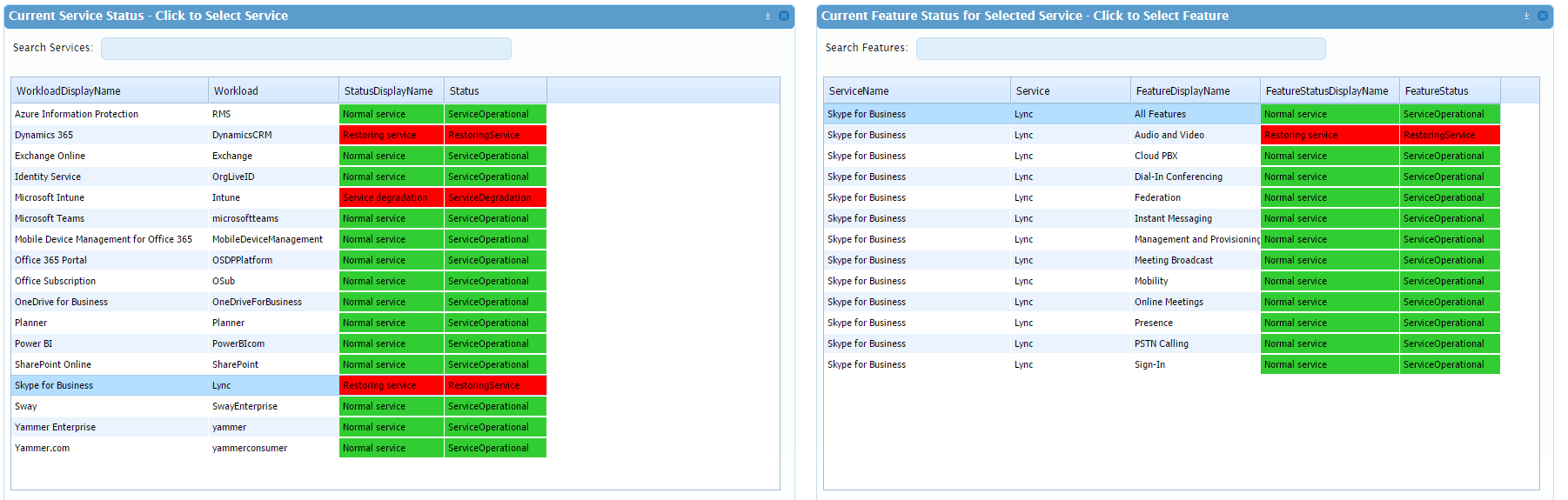
Here we find the cause: A/V components of Skype for Business were degraded for that user in the time interval where he was having the problem. A little bit of patience and some conversations with the Skype Online team had the service back up and running shortly. In fact, you can see the normal call traffic resume in the Black Box record above, and there you have it.
With SysTrack, we could find that the underlying cause for this specific user’s problem was not related to a client problem, a local network problem, or any service centrally provided by IT. Instead, there was a temporary service degradation that was resolved in short order. As essential software moves to the cloud, it is increasingly important to have the ability to gain detailed insights at the endpoint in order to identify whether the root cause of an issue can be traced back to the service provider.



Subscribe to Lakeside Updates
Receive product updates, DEX news, and more


